
Quelle matière utiliser pour générer un SBOM ?
Le SBOM, pour Software Bill Of Material, représente l’ensemble des dépendances intégrées à une application (nom, version, etc.). Cette liste est notamment intéressante pour suivre les versions et vulnérabilités présentes dans ces dépendances et en assurer les montées de versions. Elle peut même devenir obligatoire en cas d’applicabilité du Cyber Resilience Act par exemple. Les 2 formats les plus communs pour représenter un SBOM sont CycloneDX et SPDX.
A chacune des étapes du cycle de développement logiciel (SDLC), les éléments disponibles pour calculer le SBOM sont différents.
| Etapes du SDLC | Eléments disponibles |
|---|---|
| Architecture | Spécifications, exigences, macro-composants |
| Développement | Code source |
| Packaging | Livrable (binaire, image Docker, etc.) |
| Run | Environnement réel d’exécution de l’application |
Le CISA définit 5 types de SBOM :
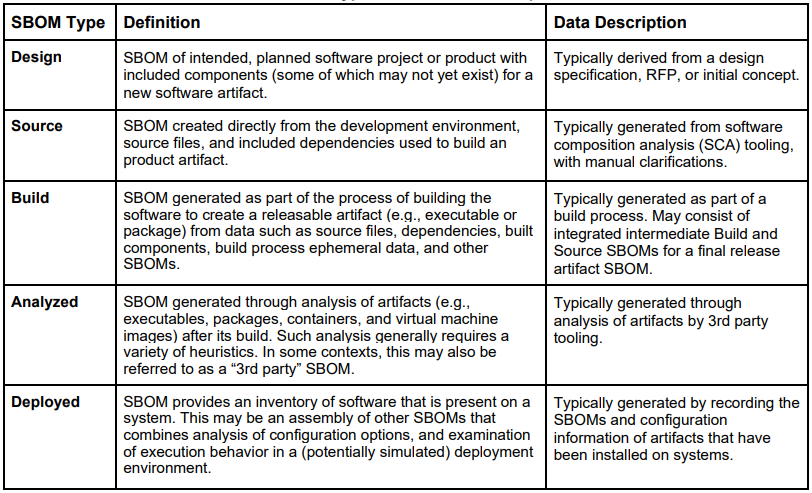
Les SBOM de type Design et Deployed sont peu courants car difficiles à générer. Le SBOM de type Build quant à lui est dépendant du système de build et nécessite des outils spécifiques (ex : cyclonedx-maven-plugin).
Pour commencer à mettre en place la génération de SBOM dans le cycle de développement, les SBOM de type Source et Analyzed sont les plus accessibles et faciles à générer par les outils du marché.
L’objecif de cet article est de démontrer les différences de contenu entre les SBOM en fonction de la matière utilisée pour les générer.
Application Java
Le projet java d’exemple utilise maven et intègre spring boot ainsi que la librairie Log4J. Les outils Trivy et Syft seront utilisés pour générer 3 SBOM à partir du :
- Code source
- Fichier JAR
- Image Docker intégrant le JAR
Le projet Java est disponible ici.
Les commandes de génération utilisées sont les suivantes :
syft -o cyclonedx-json=./sbom_source_syft.json <chemin_sources>
syft -o cyclonedx-json=./sbom_docker_syft.json <image_docker>
syft -o cyclonedx-json=./sbom_jar_syft.json <chemin_jar>
trivy fs -f cyclonedx -o sbom_source_trivy.json <chemin_sources>
trivy image -f cyclonedx -o sbom_docker_trivy.json <image_docker>
trivy rootfs -f cyclonedx -o sbom_jar_trivy.json <chemin_jar>
Le fichier comparatif des résultats est disponible ici.
La comparaison des différents SBOM peut être résumée comme suit :
| SBOM | Dépendances Java | Dépendances système |
|---|---|---|
| Sources | OUI | NON |
| JAR | OUI | NON |
| Docker | OUI | OUI |
Le fichier JAR étant une archive, l’analyse du JAR seul ou via l’image Docker permet de révéler les dépendances applicatives. L’analyse de l’image Docker remonte en supplément les dépendances du système d’exploitation utilisé dans l’image.
Application Go
La comparaison a également été réalisé avec un projet Hello World en Go intégrant la dépendance fiber.
Comme pour l’application Java, les outils Trivy et Syft sont utilisés pour générer les SBOM à partir du code source et du binaire issu de la compilation.
Le projet Go est disponible ici.
Les commandes de génération utilisées sont les suivantes :
syft -o cyclonedx-json=./sbom_sources_syft.json <chemin_sources>
syft -o cyclonedx-json=./sbom_binaire_syft.json <chemin_binaire>
trivy fs -f cyclonedx -o sbom_sources_trivy.json <chemin_sources>
trivy rootfs -f cyclonedx -o sbom_binaire_trivy.json <chemin_binaire>
Le fichier comparatif des résultats est disponible ici.
La comparaison des différents SBOM peut être résumée comme suit :
| SBOM | Dépendances Go |
|---|---|
| Sources | OUI |
| Binaire | NON |
Contrairement au Java, le binaire issu de la compilation du code Go est une boite noire ne permettant pas aux outils de déterminer quelles dépendances sont utilisées.
Conclusion
Les 2 exemples ci-dessus montrent les éléments suivants :
-
En fonction des éléments souhaités dans le SBOM (ici dépendances applicatives ou dépendances système) la matière à spécifier en entrée a un rôle important
-
Il n’est pas toujours pertinent d’utiliser la matière la plus avancée dans le SDLC pour obtenir les résultats les plus complets (le binaire Go ne permet pas de récupérer les dépendances utilisées). Dans sa conférence Cyber Resilience Act : 36 mois pour préparer vos chaînes DevOps David Robin utilise la méthaphore du Ferrero Rocher et du Chamallow : A la découpe d’un Ferrero Rocher, il est possible d’identifier tous les ingrédients qui le composent : coque en chocolat puis gaufrette, crème noisette et enfin la noisette. A la découpe d’un chamallow, il est impossible de savoir quels en sont les ingrédients. Ici l’image Docker avec l’application Java s’apparente à un Ferrero Rocher alors que le binaire Docker ressemble plus à un chamallow.
Enfin, en utilisant les 2 outils Syft et Trivy, pour une même donnée en entrée (le code source par exemple), les résultats ne sont pas toujours identiques. Certaines dépendances ne sont détectées que par un seul des deux outils. Il convient d’être attentif à ce point pour choisir l’outil le plus pertinent et adapté à la technologie utilisée.