
Introduction à l'orchestrateur de conteneurs Kubernetes
Manipuler quelques conteneurs sur des environnements de développement est une tâche facile. Lorsqu’il s’agit de faire passer ces conteneurs en production de nombreuses questions se posent :
- Comment gérer les dysfonctionnements ?
- Comment gérer les déploiements et leurs emplacements ?
- Comment gérer le scaling ?
- Comment gérer les mises à jours ?
- Comment gérer la communication entre les conteneurs ?
- Comment gérer le stockage nécessaire à la persistance des données ?
- Comment gérer les secrets et la configuration ?
- etc.
Tout gérer de manière manuelle et sans surcouche au système de conteneurs n’est pas viable, maintenable et pérenne.
Présentation de Kubernetes
Kubernetes (k8s en abrégé) est un orchestrateur de conteneurs initialement développé par Google en 2015 puis offert à la CNF (Cloud Native Computing Foundation). La solution est développée avec le langage Go (aussi à l’origine de Google).
k8s est leader sur le marché de l’orchestration de conteneurs mais dispose quand même de quelques concurrents: Docker Swarm et Apache Mesos/Marathon.
Comment fonctionne Kubernetes ?
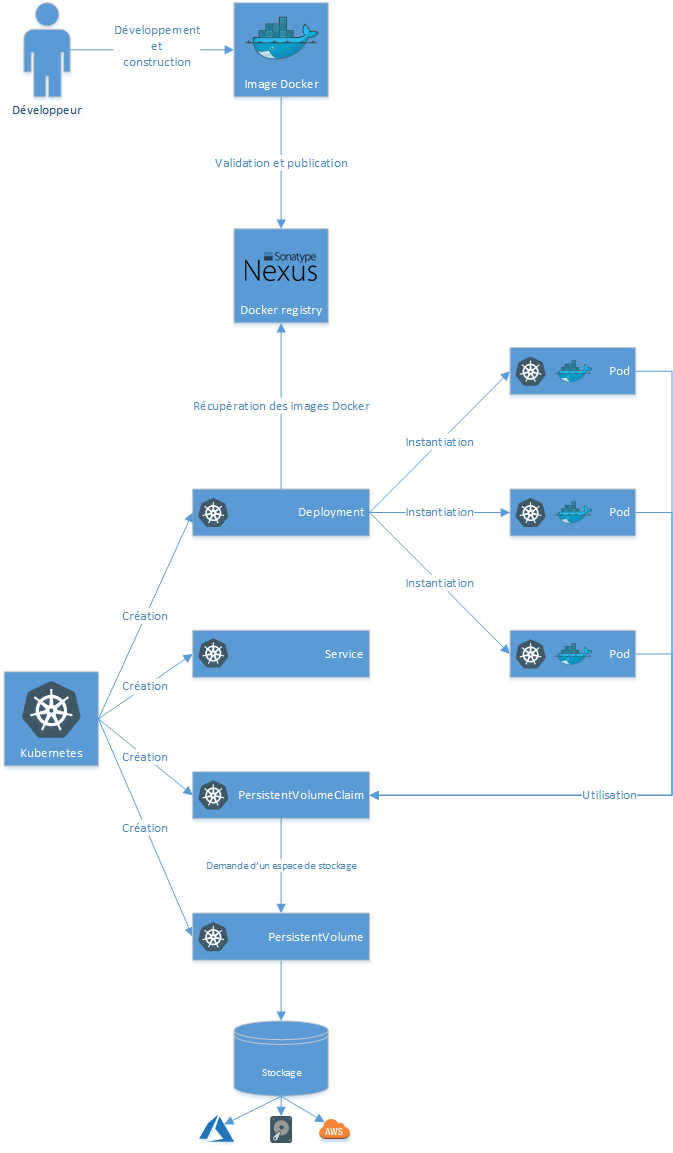
Kubernetes propose une surcouche aux moteurs de conteneurs (ex : Docker, rkt ou CRI) en introduisant la notion de pod.
Un pod est un élément composé généralement d’un conteneur, une configuration réseaux et une configuration sur le stockage. Les pods doivent être considérés comme jetable, ils sont instanciés et détruits au cours de la phase de run d’une application.
Ces pods sont gérés par des deployments. Un deployment définit la configuration des pods, le nombre de répliquas souhaités, la stratégie de mise à jour des pods, etc. C’est grâce au deployment que le nombre de pods actifs demandé est maintenu sur un environnement. En cas de défaillance d’un pod, il est supprimé et un nouveau pod est instancié.
Pour gérer le load balancing et la communication avec les pods, k8s introduit la notion de service comme point unique de communication avec plusieurs pods. Les pods étant “mortels”, il n’est pas possible de se baser directement sur leurs IPs.
Pour la même raison, aucune donnée persistante ne peut être stockée au niveau des pods. Pour persister de la donnée, des PersistentVolumes pointant vers des volumes réseaux, des volumes sur AWS (EBS), Azure, etc sont créés au niveau du cluster k8s. Une fois ces volumes créés, un PersistentVolumeClaim doit être créé pour réserver un espace sur un PersistentVolume.
La vision présentée ci-dessus est une introduction. De nombreux autres paramètres et concepts sont proposés par k8s pour définir de manière très fine la gestion des conteneurs.
Exemple concret :
- Création d’un **deployment **spécifiant 3 répliquas de pods basés sur l’image Docker d’un service web en Java exposant le port 9000.
- Création d’un service exposant le port 80 et redirigeant vers le port 9000 des 3 pods du service web. - Création d’un **PersistentVolume **de 100Go basé sur un volume EBS de AWS
- Création d’un PersistentVolumClaim de 10Go avec le mode d’accès “ReadOnlyMany” permettant au volume d’être monté en lecture seul sur plusieurs nodes (worker K8s).
 Pour simplifier la compréhension, les exemples ci-dessus sont basés sur l’utilisation du moteur de conteneurs Docker et de son format d’images associé. Kubernetes gère également le runtime rkt de CoreOS.
Pour simplifier la compréhension, les exemples ci-dessus sont basés sur l’utilisation du moteur de conteneurs Docker et de son format d’images associé. Kubernetes gère également le runtime rkt de CoreOS.
Pour faciliter l’intégration des moteurs de conteneurs, Kubernetes propose la CRI (Container Runtime Interface) composée d’un API, de spécifications et de librairies. CRI-O est une implémentation de CRI proposant une alternative plus légère au runtime Docker tout en supportant son format d’image. L’utilisation de CRI-O dispense donc de l’utilisation du runtime Docker au niveau des nodes k8s.
Concernant l’installation de Kubernetes, il peut être installé on-premises ou sur un cloud public (AWS, Azure, IBM, etc.). Un bon moyen de tester Kubernetes est de l’installer sur un poste local via minikube.
Comment Kubernetes répond aux questions posées en introduction ?
Les Deployments répondent aux problématiques :
- de dysfonctionnement en assurant que le nombre de répliquas actifs demandé soit toujours respecté.
- de déploiement sur des emplacements spécifiques (node) avec la notion d’affinity et de nodeSelector
- de scaling en ajustant le nombre de répliquas en fonction des besoins
- de mise à jour en spécifiant la stratégie adéquate et en utilisant les mécanismes de rollback
Les Services répondent aux problématiques de communication avec les conteneurs.
Les PersistentVolumes et PersistentVolumeClaims répondent aux problématiques de persistance des données.
Les ConfigMaps répondent aux problématiques de configuration en sortant ces éléments liés aux environnements (préproduction, production, etc.) des conteneurs.
Enfin, la notion de Secrets permet de garder le contrôle sur les données sensibles de type mot de passe, clé d’API, etc.